
엔비디아, AI 판 뒤흔들 오픈소스 '네모트론' 전격 공개! (딥시크 R1 넘어선 추론 괴물?)
안녕하세요!
하루가 다르게 격변하는 인공지능(AI) 모델 경쟁 속에서, 하드웨어의 절대 강자 엔비디아가 또 한 번 게임의 판도를 바꿀 강력한 카드를 꺼내 들었습니다! 바로 오픈 소스 추론 모델 '라마-3.1 네모트론(Llama-3.1 Nemotron)'에 이어, 최근 '라마-3.3 네모트론(Llama-3.3 Nemotron)' 제품군을 전격 공개한 것인데요.
특히 가장 주목받는 '네모트론 울트라(Nemotron Ultra)' 모델은, 현존 최강의 오픈 소스 추론 모델 중 하나로 꼽히던 '딥시크-R1(DeepSeek-R1)'보다 절반도 안 되는 크기(매개변수 기준)로 대등하거나 일부 영역에서는 더 뛰어난 성능을 보여주며 AI 커뮤니티를 뜨겁게 달구고 있습니다.
단순히 성능만 좋은 것이 아닙니다. 엔비디아는 이 강력한 모델을 연구 및 상업적 용도로 자유롭게 사용할 수 있도록 오픈 소스로 공개하며, 고성능 AI 기술의 민주화에 앞장서겠다는 의지를 분명히 했습니다.
오늘은 엔비디아가 야심 차게 내놓은 라마 네모트론 모델이 무엇인지, 어떤 기술적 혁신을 담고 있는지, 그리고 AI 생태계에 어떤 파장을 일으킬지 쉽고 상세하게 파헤쳐 보겠습니다!

왜 '추론(Reasoning)' 능력이 중요할까? AI 에이전트 시대를 열다
본격적으로 네모트론을 알아보기 전에, 왜 엔비디아가 '추론' 능력에 집중한 모델을 내놓았는지 짚고 넘어가야 합니다. AI 에이전트 시대가 도래하면서, AI는 단순히 주어진 정보에 답하는 것을 넘어 복잡한 문제를 스스로 분석하고, 숨겨진 연관성을 찾아내며, 논리적인 판단을 내려 자율적으로 작업을 수행하는 능력이 중요해졌습니다.
이러한 능력의 핵심이 바로 '추론(Reasoning)'입니다.
- 추론이란? 주어진 정보를 바탕으로 새로운 결론이나 판단을 이끌어내는 사고 과정입니다. AI에서의 추론은 ▲다단계 문제 해결 ▲논리적 연역 및 귀납 ▲인과 관계 파악 ▲가설 생성 및 검증 등 고차원적인 지적 능력을 포함합니다. (참고문헌 1)
- AI 에이전트와 추론: 고객 지원 자동화, 공급망 최적화, 금융 전략 실행, 과학 연구 가설 생성, 의료 진단 보조 등 복잡하고 동적인 환경에서 AI 에이전트가 효과적으로 작동하기 위해서는 강력한 추론 능력이 필수적입니다.
- 테스트 시간 스케일링 (Test-time Scaling): 추론 모델은 종종 '테스트 시간 스케일링' 기법을 활용하여 성능을 극대화합니다. 이는 추론(답변 생성) 시 더 많은 계산 자원과 시간을 투입하여 ▲다양한 해결 경로를 탐색하고(예: 생각의 사슬 확장) ▲여러 답변 후보 중 최상의 것을 선택하거나(예: Best-of-N) ▲스스로 답변을 검증(예: Self-verification)하는 과정을 거쳐 답변의 질과 추론의 정확도를 높이는 방식입니다. (참고문헌 2)
엔비디아 네모트론은 바로 이러한 고성능 추론 능력을 갖춘 AI 모델을 누구나 쉽게 활용하여 강력한 AI 에이전트를 구축할 수 있도록 지원하는 데 목표를 두고 있습니다.
엔비디아 라마 네모트론: 강력한 추론 능력과 효율성을 겸비한 오픈 모델 삼형제
엔비디아는 사용자의 다양한 요구사항과 컴퓨팅 환경에 맞춰 선택할 수 있도록 라마 네모트론 제품군을 세 가지 크기로 출시했습니다.
 - 8B") |
| 네모트론 나노 (Nano) - 8B |
- 네모트론 나노 (Nano) - 8B:
- 메타의 '라마 3.1 8B' 모델을 기반으로 미세조정되었습니다.
- PC 및 엣지 디바이스 환경에서 최고의 정확도를 내도록 설계되어, 온디바이스 AI 환경에서의 고성능 추론을 목표로 합니다.
 |
| 네모트론 슈퍼 (Super) - 49B |
2. 네모트론 슈퍼 (Super) - 49B:
* '라마 3.1 70B' 모델을 기반으로 증류(Distillation) 과정을 거쳐 490억 개 파라미터로 크기를 줄였습니다. (참고: 영문 블로그에서는 Llama 3.3 70B 기반이라고 명시되었으나, 출시 모델명은 Llama 3.1 기반일 수 있음. 모델 카드 확인 필요)
* 데이터센터 GPU 환경에서 최고의 처리량(Throughput) 대비 정확도를 목표로 합니다. 즉, 효율적인 추론 성능에 초점을 맞춘 모델입니다.
 |
| 네모트론 울트라 (Ultra) - 253B |
3. 네모트론 울트라 (Ultra) - 253B:
* '라마 3.1 405B' 모델을 기반으로 증류하여 2530억 개 파라미터로 최적화되었습니다.
* 멀티 GPU 데이터센터 서버 환경에서 최고 수준의 에이전트 정확도를 목표로 합니다. 가장 강력한 추론 성능을 제공하는 플래그십 모델입니다.
이 모델들은 모두 메타의 오픈 모델인 라마(Llama)를 기반으로 하며, 엔비디아가 검증한 데이터셋과 자체 생성한 고품질 합성 데이터를 사용하여 훈련되었습니다. 무엇보다 허깅페이스(Hugging Face)를 통해 모델 가중치가 공개되어 있어, 연구는 물론 상업적인 용도로도 자유롭게 활용할 수 있다는 점이 가장 큰 특징입니다.
네모트론 울트라(253B) 집중 분석: 딥시크 R1을 넘어서다?
이번 발표에서 가장 화제가 된 것은 단연 네모트론 울트라 253B 모델입니다. 이 모델이 주목받는 이유는 다음과 같습니다.
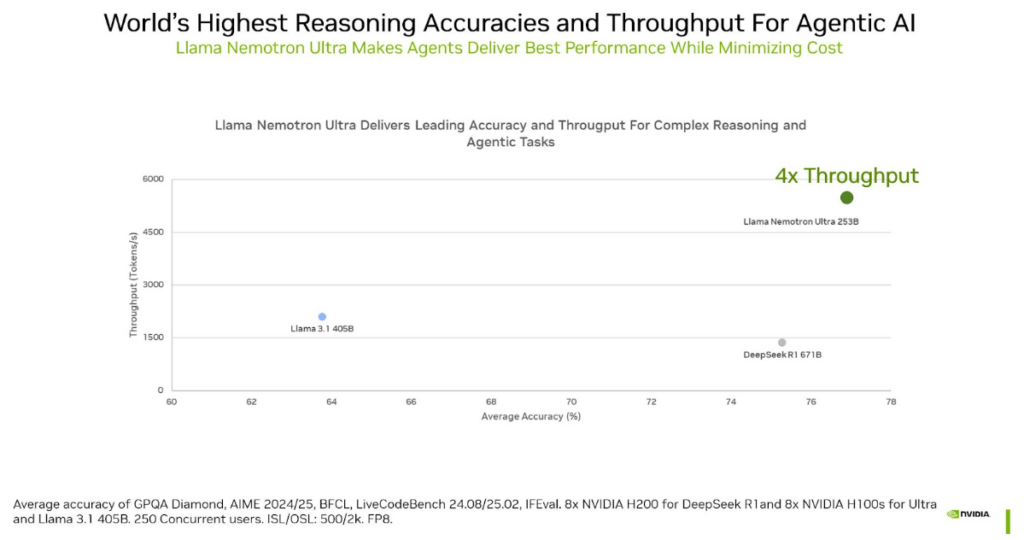 |
| Llama Nemotron Ultra는 뛰어난 정확도와 놀라운 처리량을 모두 제공합니다 |
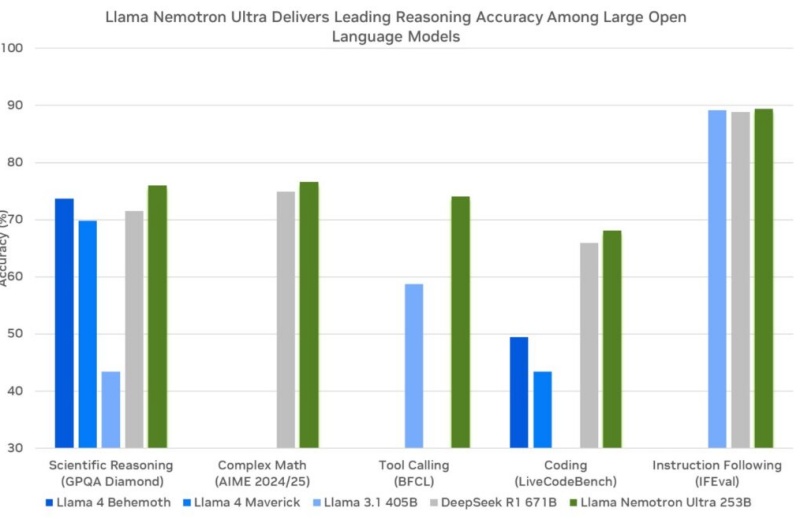
- 경쟁 모델 대비 효율성: 6710억 개의 파라미터를 가진 딥시크-R1(DeepSeek-R1 671B) 모델과 비교했을 때, 네모트론 울트라는 절반 이하인 2530억 개의 파라미터를 가집니다. 모델 크기가 작다는 것은 일반적으로 추론 시 더 적은 컴퓨팅 자원(GPU 메모리, 연산량)을 요구하고 더 빠른 속도를 낼 수 있음을 의미합니다.
- 인상적인 성능: 더 작은 크기에도 불구하고, 네모트론 울트라는 다양한 벤치마크에서 딥시크-R1과 대등하거나 뛰어난 성능을 보여주었습니다.
- GPQA (Google-proof Q&A): 복잡한 추론 능력을 요구하는 이 벤치마크에서 네모트론 울트라(76.01%)는 딥시크-R1(71.5%)을 능가했습니다.
- LiveCodeBench (코드 생성): 특정 기간 평가에서 네모트론 울트라가 딥시크-R1보다 높은 성능을 기록했습니다.
- MATH500 / AIME25 (수학 문제 해결): 수학 분야에서는 딥시크-R1이 여전히 소폭 우세(AIME25: 79.8% vs 72.5%, MATH500: 97.3% vs 97.0%)를 보였지만, 네모트론 울트라 역시 매우 높은 성능을 달성했습니다.
- 전반적인 평가: 특정 수학 분야를 제외하면, 전반적인 추론 성능, 지시 이행 능력, 에이전트 관련 벤치마크에서는 네모트론 울트라가 더 뛰어난 결과를 보였다고 엔비디아는 강조합니다.
- 단일 서버 실행 가능: 최적화된 아키텍처 덕분에 엔비디아 H100 GPU 8개로 구성된 단일 서버에서도 실행 가능하여, 상대적으로 접근성이 높습니다.
이러한 결과는 엔비디아가 단순히 모델 크기를 줄이는 것을 넘어, 매우 효율적인 방식으로 모델을 훈련하고 최적화했음을 시사합니다. 출시 3개월 만에 여러 모델에게 성능을 추월당하고 있는 딥시크-R1의 사례는 오픈 소스 LLM 경쟁이 얼마나 치열하고 빠르게 진행되고 있는지를 보여주는 단적인 예입니다.
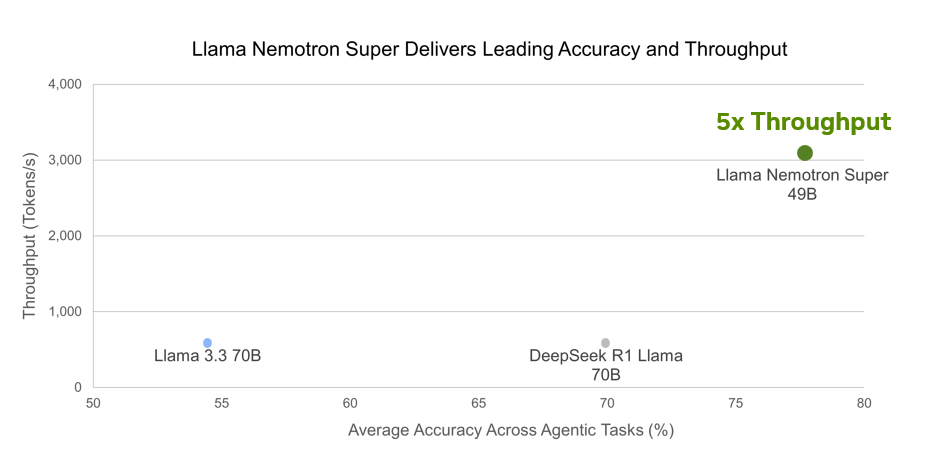
 |
| Llama Nemotron Super는 에이전트 작업에 대해 가장 높은 정확도와 처리량을 제공하여 추론 비용을 낮춥니다 |

네모트론의 탄생 비결: 엔비디아의 첨단 기술 집약

그렇다면 엔비디아는 어떻게 더 작은 모델로 이러한 고성능을 달성했을까요? 네모트론 모델 개발에는 엔비디아의 다양한 AI 연구 및 기술이 집약되었습니다. (참고문헌 3 - NVIDIA Blog Post)
- 정교한 후훈련(Post-training) 파이프라인:
- 1단계: 증류 (Distillation) 및 신경망 아키텍처 탐색 (NAS): 더 큰 기반 모델(예: 라마 3.1 405B)의 지식을 더 작은 모델(예: 네모트론 울트라 253B)로 효율적으로 이전하는 지식 증류(Knowledge Distillation) 기법과 함께, 특정 하드웨어(엔비디아 GPU)에서 최적의 성능을 내도록 모델 구조 자체를 탐색하고 설계하는 NAS(Neural Architecture Search) 기술을 적용하여 모델 크기를 최적화했습니다. (참고문헌 4 - Puzzle NAS Paper 언급) 이 과정에서 어텐션 레이어 생략, 피드포워드 네트워크(FFN) 통합 및 압축률 조정 등 구조적 변형을 통해 메모리 사용량과 연산 부담을 줄였습니다.
- 2단계: 지도 미세조정 (Supervised Fine-Tuning, SFT): 엔비디아가 자체적으로 큐레이션한 고품질 프롬프트와 합성 데이터(수학, 코드, 대화, 도구 활용 등)를 사용하여 모델의 기본적인 지시 따르기 및 다양한 작업 능력을 향상시켰습니다. 특히, 딥시크-R1이 강점을 보이는 수학, 코드, 과학 분야의 데이터를 선별적으로 증류하여 네모트론의 추론 능력을 강화했습니다. 이 단계에서 '추론 토글(Reasoning Toggle)' 기능이 구현되었습니다.
- 3단계: 강화학습 (Reinforcement Learning, RL): 엔비디아 니모(NeMo) 프레임워크를 활용하여 GRPO(Group Relative Policy Optimization), REINFORCE 알고리즘, HelpSteer 데이터셋 기반 RLHF(인간 피드백 기반 강화학습) 등을 적용하여 모델의 대화 능력, 지시 이행 능력, 사용자 의도와의 정렬(alignment)을 더욱 정교하게 다듬었습니다.
- 추론 토글 (Reasoning Toggle) 기능:
- 앤트로픽의 '클로드 3.7 소네트'와 유사하게, 사용자가 시스템 프롬프트(System Prompt)를 통해 모델의 '추론 모드(Reasoning ON)'와 '일반 모드(Reasoning OFF)'를 선택할 수 있습니다.
- 간단한 작업에는 불필요한 추론 과정을 생략하여 응답 속도와 효율성을 높이고(일반 모드), 복잡한 문제 해결이나 깊이 있는 분석이 필요할 때는 추론 기능을 활성화하여 정확도를 극대화(추론 모드)할 수 있습니다. 이는 하나의 모델로 다양한 작업 요구사항에 유연하게 대응할 수 있게 해주는 매우 실용적인 기능입니다.
- 네모트론 울트라의 벤치마크 결과를 보면, 추론 모드를 켰을 때 MATH500 정확도가 80.40%에서 97.00%로, AIME25는 16.67%에서 72.50%로 비약적으로 향상되는 것을 볼 수 있습니다.
- 개방적인 접근:
- 엔비디아는 모델 가중치뿐만 아니라, 후훈련 과정에서 사용된 데이터의 상당 부분(약 3천만 샘플)과 모델 훈련 레시피(기술 보고서 형태)까지 공개했습니다. 이는 개발자들이 네모트론 모델을 이해하고, 자체적으로 커스터마이징하거나 유사한 고성능 모델을 개발하는 데 큰 도움을 줄 것입니다.
네모트론의 활용 가능성 및 기대 효과
강력한 성능과 효율성, 그리고 오픈 소스 라이선스를 갖춘 라마 네모트론 모델은 다양한 분야에서 활용될 잠재력이 매우 큽니다.
- 엔터프라이즈 AI 에이전트 구축: 복잡한 업무 자동화, 데이터 분석 및 보고서 생성, 고객 지원 고도화 등 기업 환경에서의 AI 에이전트 개발에 핵심 엔진으로 사용될 수 있습니다.
- 챗봇 및 대화형 AI: 향상된 지시 이행 능력과 자연스러운 대화 능력으로 더욱 만족스러운 사용자 경험을 제공하는 챗봇 개발이 가능합니다.
- 검색 증강 생성 (RAG): 외부 데이터베이스나 문서를 참조하여 답변의 정확성과 신뢰도를 높이는 RAG 시스템 구축에 효과적입니다.
- 코드 생성 및 개발 지원: 뛰어난 코드 생성 능력을 바탕으로 개발 생산성을 향상시키는 도구로 활용될 수 있습니다.
- 다국어 지원: 영어 외에도 독일어, 프랑스어, 스페인어, 힌디어, 태국어 등 다양한 언어를 지원하여 글로벌 서비스 개발에도 유리합니다. (최대 12만 8천 토큰의 긴 컨텍스트 처리 능력 포함)
- 과학 및 연구: 복잡한 과학 문제 해결, 가설 생성, 데이터 분석 등 연구 활동을 보조하는 강력한 도구가 될 수 있습니다.
- 교육 및 학습: 맞춤형 학습 콘텐츠 생성, 질의응답 시스템 등 교육 분야에서의 활용도 기대됩니다.
엔비디아는 네모트론 출시를 통해 고성능 LLM의 오픈 소스 생태계를 더욱 활성화하고, 자사의 GPU 하드웨어와 함께 추론 중심 AI 시스템 구축을 위한 강력한 기반 모델로서의 입지를 다질 것으로 기대하고 있습니다.
오픈 소스 AI의 새로운 지평을 열다
엔비디아의 라마 네모트론 모델 출시는 단순히 또 하나의 강력한 AI 모델 등장을 넘어, 오픈 소스 AI 생태계에 중요한 의미를 던집니다. 딥시크-R1과 같은 최첨단 모델을 빠르게 따라잡고 일부 능가하는 모델을 더 효율적인 크기로 구현하여, 누구나 자유롭게 사용하도록 공개했다는 점은 AI 기술 발전과 민주화에 큰 기여를 할 것입니다.
특히 '추론 토글' 기능과 같이 실용성을 높인 설계와 모델 훈련 과정의 투명한 공개는 개발자들에게 매력적인 선택지를 제공하며, 앞으로 더욱 치열해질 AI 에이전트 시장 경쟁에서 엔비디아가 중요한 플레이어로 부상할 것임을 예고합니다.
하드웨어뿐만 아니라 소프트웨어, 특히 최첨단 AI 모델 개발에서도 압도적인 역량을 보여주기 시작한 엔비디아. 그들이 열어갈 오픈 소스 AI의 새로운 시대가 더욱 기대됩니다!
참고문헌 (References):
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2017). Building machines that learn and think like people. Behavioral and brain sciences, 40, e253. (인간과 같은 학습 및 추론 능력을 갖춘 기계 구축에 대한 논의)
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. (생각의 사슬 프롬프팅 등 LLM의 추론 능력 향상 기법 연구)
- NVIDIA Developer Blog. (2024, July 9). Build Enterprise AI Agents with Advanced Open NVIDIA Llama Nemotron Reasoning Models. https://developer.nvidia.com/blog/build-enterprise-ai-agents-with-advanced-open-nvidia-llama-nemotron-reasoning-models/ (네모트론 모델 개발 과정 상세 설명)
- NVIDIA Research. (2024). Puzzle: Distillation-Based NAS for Inference-Optimized LLMs. (언급된 NAS 관련 기술 보고서 - 실제 링크는 확인 필요)
- Zhao, Z., Yu, L., Li, C., Zhang, H., Chen, T., Cheng, M., ... & Zhang, Y. (2024). Deepseek-coder: When the large language model writes programming language. arXiv preprint arXiv:2401.14196. (딥시크 코더 관련 논문, 딥시크 모델군의 기술적 배경 참고)

{kind=link}